The central concept of this project is that we will provide:
The data store is also informally referred to as a "data bucket". One of the aims of the project is to hide the implementation details of the data store so that a client application will only see one bucket of data.
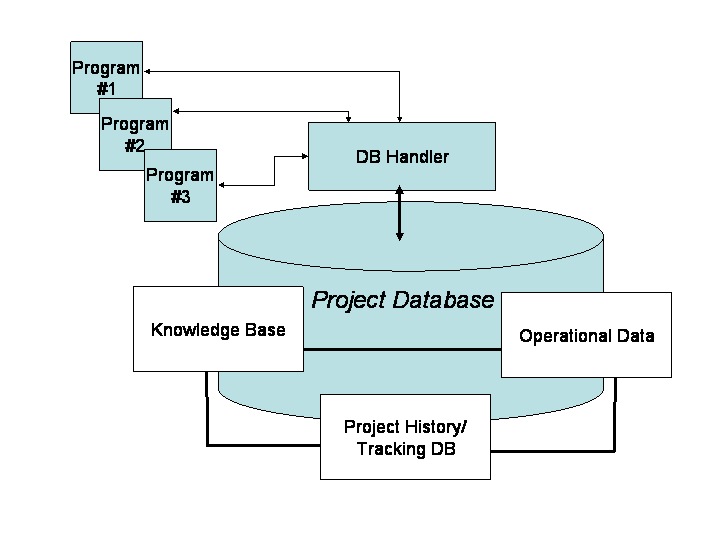
The final project database will consist of three conceptual components:
The three databases are separate but related - as programs are run they may wish to store operational data, the resulting jobs are stored in the tracking database, and the output data may be stored in the project information database.
The three databases are illustrated in the figure below:
Issues that need to be resolved include what data needs to be stored, and how. For example: within CCP4i a project consists of a directory which contains a "database file" which stores details of each job run, in addition the directory also contains data files which have been imported or generated during the structure determination process.
The project data handler will provide a mechanism for applications (programs or scripts) to store and recover data from a common place without having to know about the implementation details of the data storage (i.e. how the data is actually stored). It will act as a server and handle different client applications accessing a single database simultaneously, as illustrated schematically in the figure below:
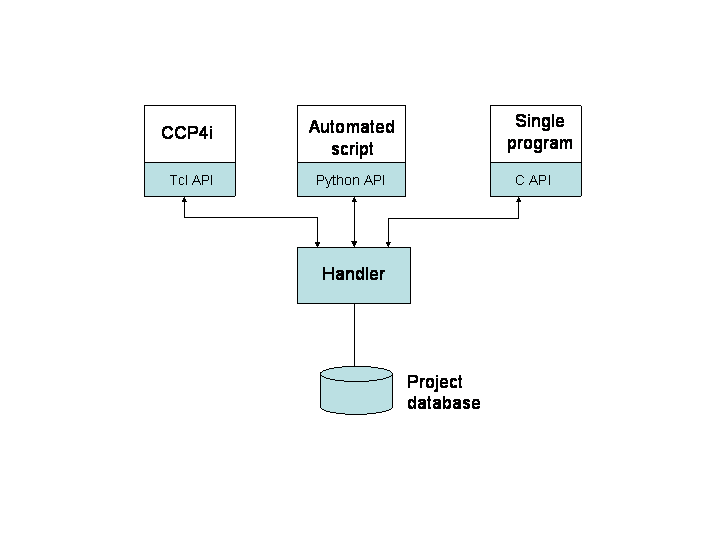
The components are:
The three basic components of the system and their interactions are represented schematically below:
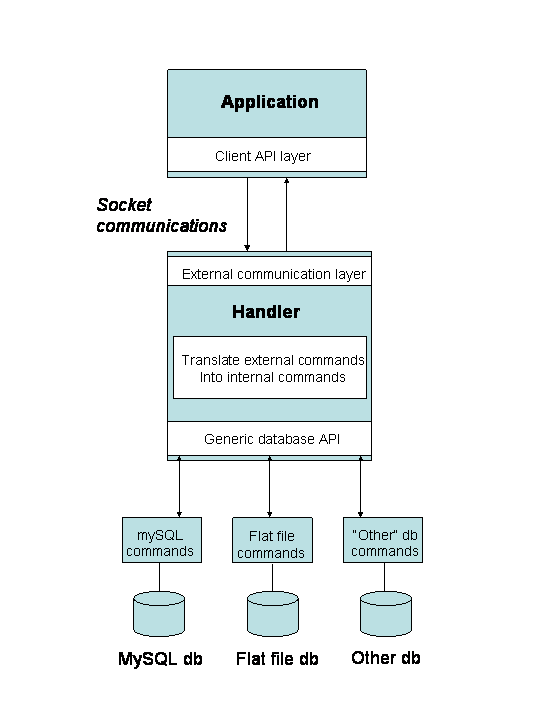
We need to provide the following components:
The handler itself can be thought of consisting of three components:
Visualisation tools are applications which take the information stored in the data store and present different views that help the end user to better understand relationships within that data.
A simple example of a visualisation tool is the job list within CCP4i - this shows some basic attributes of each job within a project and allows the user to interact with the database by selecting jobs and then performing operations such as listing and viewing the associated input and output files, or rerunning the task with the same parameters.
More sophisticated tools can be envisaged, for example: showing the job list graphically as a "network diagram", which would make it easier to see pathways through the structure solution process and understand how the final result was arrived at.
There are five components which need to be prototyped:
The prototype handler will not need to consider security and authentication issues.
Initially we will consider a minimal database as the prototype data store. This can be thought of as having a hierarchical structure: the database will contain one or more projects, each of which will contain one or more jobs. Each job can have one or more associated facts and one or more associated dingbats:
| Database Element | Description | Attributes |
|---|---|---|
| Project |
A collection of jobs which have something in common, for example steps towards determining the structure of a single protein. Project names must be unique. |
|
| Job |
A job is an instance of an operation, such as a run of a program or script. |
|
| Fact |
A fact is some item of information associated with a job, for example the solvent content or cell parameters. Note that facts do not have to have unique names. |
|
| Dingbat |
A dingbat is storage of some complex object, for example a pickled python object. Note that dingbats do not have to have unique names. Issues:
|
|
The relationships between these elements are represented schematically in the figure below:
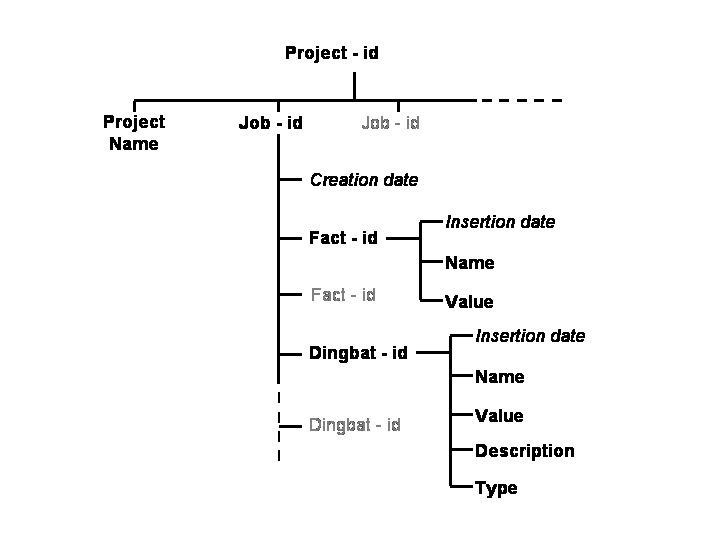
Functions for interacting with this "generic" database are outlined below (Generic Database API Functionality). The generic minimal database and the generic functions will be implemented in e.g. mySQL or CCP4i's def file reading functions.
The API within the handler to the minimal database will provide core functionality to manipulate the data outlined above:
| Function | Description | Input | Return | Example |
|---|---|---|---|---|
| Open a project | Create a new project database (or open an existing database) | OpenProject project | ||
| Create a new job | Create a new job id within the specified project and set the creation date automatically to be the date and time that the handle was created. Return the job id. | job_id = NewJob project | ||
| Store a fact | Create a new fact for a specified job in a specified project. The fact will have name and value attributes specified by the calling application. The insertion date for the fact will automatically be set to the date and time that the new item was stored. | SetData project job_id name value | ||
| Retrieve a fact | Request the value associated with the most recent fact stored in a specific project for a specific job and specific name. "Most recent" means the fact with the latest insertion date. Return the matching value. | value = GetData project job_id name | ||
| Import a dingbat into the database | Create a new dingbat for a specified job in a specified project. The dingbat will have name, description, type and value attributes specified by the calling application. The insertion date for the dingbat will automatically be set to the date and time that the new item was stored. | ImportDingbat project job_id name description type value | ||
| Retrieve the description and type information of a dingbat | Fetch the description and type attributes of a dingbat for a specified job in a specified project. | description_and_type = DescribeDingbat project job_id name | ||
| Export a dingbat from the database | Fetch the value associated with the most recent dingbat stored in a specific project for a specific job and specific name. "Most recent" means the dingbat with the latest insertion date. Return the matching value. | object = ExportDingbat project job_id name | ||
| Delete a dingbat from the database | Remove a dingbat and its associated data from a specific project for a specific job and specific name. | DeleteDingbat project job_id name |
Other query functions will be required:
| Function | Description | Input | Return | Example |
|---|---|---|---|---|
| List projects | Return a list of names of all the projects in the database. | project_list = ListProjects | ||
| List jobs | Return a list of job ids in a specified project | job_list = ListJobs project | ||
| List facts | Return a list of the facts associated with a specific job in a specific project | fact_list = ListFacts project job_id | ||
| List dingbats | Return a list of the dingbats associated with a specific job in a specific project | dingbat_list = ListDingbats project job_id |
These are the commands recognised by the handler when they are recieved from an external application. The handler will offer a set of database commands which map directly onto the functions outlined in the Generic Database API Functionality section above. It will also offer a set of administrative commands which can be invoked by the application to do the following:
| Function | Description | Input | Return | Example |
|---|---|---|---|---|
| Connect to (log into) the handler | The application provides information which tells the handler e.g. which user it is operating on behalf of. This is like e.g. logging into a remote computer and having to supply username and password information. | Connect | ||
| Disconnect from (log out of) the handler | An application which is logged in can terminate the connection (this is like typing "exit") | Disconnect | ||
| Shut down the server | Tell the handler to terminate all client connections and then stop running. | Shutdown |
The mode of operation that is envisaged is as follows:
The client API library is a set of functions which will be provided to applications to allow them to communicate with the handler.
Communications with the handler will be via a set of commands that the handler recognises. These commands will be packaged in some protocol which allows the the handler to verify them (for example HTTP). The client API library will provide commands in different languages which will do the following:
The client API will also perform any transformations of the data (e.g. base64 encoding/decoding) that are required.
The client API library will therefore offer a range of functions which directly map onto the functions offered by the handler.
The prototype visualiser is a client application which will provide a graphical interface to allow a user to explore the project information held in the database. The explorer would provide three windows, one each for listing projects, jobs and facts. The user can select a project name and the list of jobs is updated to show those jobs within that project. The user can then select a job and the list of facts is updated to show the facts for that job.
A cartoon of what the explorer might look is shown below:
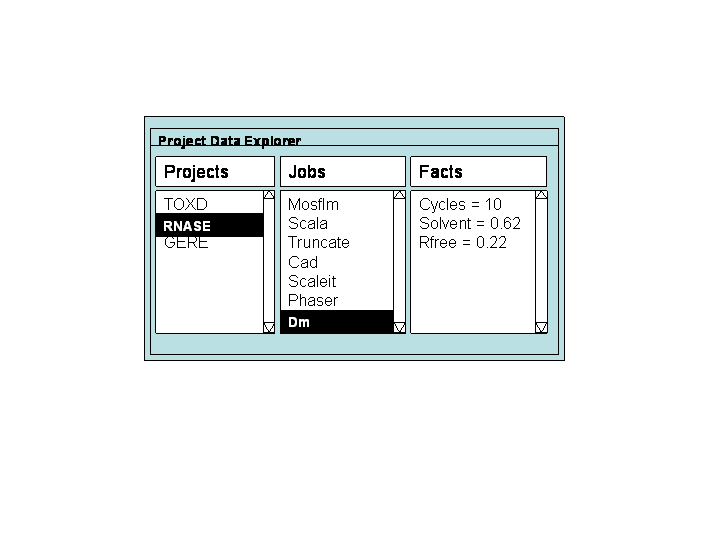
The explorer will need to be synchronised with the database. This could be done in one of two ways:
Mode of use: single user running a single handler on a single machine. The user may run one or more applications which can communicate simultaneously with the handler to store and retrieve data from the database.
Two broad modes of use are envisaged:
Persistence of connections in different modes
The current prototype implicitly considers automated systems in which connections with the database are short-lived and last only as long as it takes to send a request to the handler and send back the response. In the case of "manual" systems such as CCP4i the connection between the application (i.e. CCP4i) and the handler may be more persistent and a large number of requests and responses may be exchanged for a single connection, often over a long period of time.
However it might be better to think in terms of client types - different types of client applications will have different requirements.
Communications between the handler and the applications take a number of forms:
Comments on broadcast communications: these were needed by the CCP4i prototype as a way for the handler to inform the application of changes e.g. updates to the database. This may be required for client applications which maintain a persistent connection with the handler.
The communications between the client applications and the handler (via the client API) need to be defined. There are two components:
There are a number of requirements for the communication protocol, for each type of communication. We can dig for these by writing workflows for the interactions between the handler and different types of client.
We also need to consider the format of the responses which are sent back from the handler to the application. In this case as well as returning the actual data which has been requested (for example a new job id, or the value associated with a particular fact) the handler will also need to have some way of communicating whether or not the request
The protocols which have been suggested so far are:
The advantage of using a more sophisticated protocol is that it allows some basic validation of requests from the client (e.g. is it the right length? is it the correct format?). It also provides a way of separating the return value from the result of a request, and for distinguishing between responses and broadcasts.
See also separate document: DB Handler Communication Protocols