This document is intended to give an overview of how project directories are implemented in CCP4i. It is probably useful if it is combined with some practical experience of using CCP4i.
CCP4i operates using project directories which are defined by the user. CCP4i opens one project at a time, but the user can switch between different projects at will during a CCP4i session.
Within each project CCP4i keeps a list of jobs run by the user in that project - for each job CCP4i records:
Some of this information is displayed as a job list in the main CCP4i window. This job list acts as part of the interface for the user to interact with the project history, for example vieweing or deleting files associated with a given job or set of jobs, deleting a complete job record, reviewing the parameters used in or rerunning an old job. (See the information on the "Database Utility" in the External Resources section.
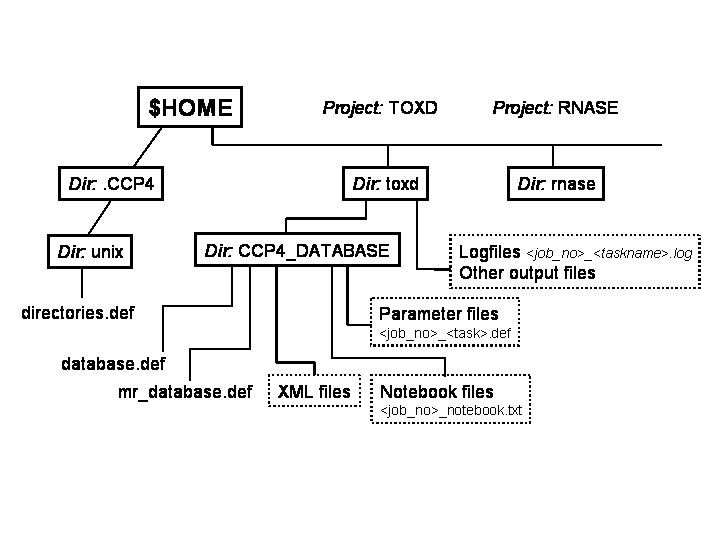
The directory structure and relevant files for CCP4i projects are shown schematically below:
This schematic is intended to show where the different components are. The functions of each of the components are outlined below:
The file $HOME/.CCP4/<OPSYS>/directories.def file stores the list of project names (referred to as project aliases, see below) and the corresponding directory paths. <OPSYS> is determined by the platform (either unix or windows at present). For details of the CCP4i .def file format see the External Resources section below.
In addition it is possible to associate aliases with commonly used (non-project) directories. In this case no CCP4_DATABASE subdirectory is created for the named directory. By default there is always an alias for the temporary directory. These aliases are useful for pointing to directories where data files are stored, for example a directory containing a collection of possible molecular replacement models.
directories.def also stores the alias of the current project that CCP4i is using, and the alias of that currently used by the CCP4 Molecular Graphics package.
A project in CCP4i consists of a project directory associated with a project alias. There are no restrictions on what constitutes a "project" - the definition as far as CCP4i is concerned is arbitrary, and it is left up to the user to decide how best to divide their work up into projects. Also, there are no formal relationships defined between projects in CCP4i - so for example it is possible to create a new project directory as a subdirectory of an existing project directory.
The project directory is simply a locally accessible directory. If the directory doesn't exist when the user specifies it then CCP4i will offer to create it for them.
The data stored in the project directory includes:
The alias is used within CCP4i to help with file browsing, and to locate input and output files. There are no restrictions on the number of characters that can be used in a project alias name, however there are some restrictions on the types e.g. no whitespace.
The subdirectory CCP4_DATABASE is created in the project directory when the project is first defined within CCP4i, and is used to store the following information:
The list of jobs which have been run in that project (the project history information) is stored in a
file called database.def.
For each job this stores STATUS, DATE, INPUT_FILES, OUTPUT_FILES, LOGFILE, TASKNAME and TITLE.
The database of information for molecular replacement trial models, in a file called mr_database.def.
Parameter files corresponding to each of the jobs that have been run in that project.
The names of these files are not stored, instead they are constructed using the following naming scheme:
<job_no>_<taskname>.def
e.g. for job number 400 I ran the molrep task, so the parameters are stored in the file 400_molrep.def.
Notebook entry files associated with specific jobs.
The notebook files use the naming scheme: <job_no>_notebook.txt. A job will only have a notebook file
associated with it if the user has explicitly created one.
Some XML files generated from particular tasks (e.g. matthews_coef and mr_analyse) are also stored here.
Ideally a non-CCP4i should be able to interact with the projects using the same Tcl commands as those used by CCP4i. In practice, although there are a number of Tcl procedures in the core CCP4i code for dealing with projects, unfortunately the CCP4i core code is not currently very well organised and does not offer a consistent and "clean" interface for non-CCP4i programs.
I'm intending to do some work on improving these APIs in the next few months and would welcome any input into this work if you are interested in hooking into the CCP4i project structure in some way -pjb.
As part of the BIOXHIT project the way the CCP4i project database is implemented will be changed. The content of the job database will be expanded to enable project and data tracking, and access to the database will be mediated by a separate "database handler" process which will hide many of the details of the project and database implementation from the application process.
This is a list of URLs which might be useful in expanding on the above, however it is not intended to be definitive but merely to act as a starting point.
User perspective on projects in CCP4i
CCP4i programming